Here is a quote attributed to Darwin:
"It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is the most adaptable to change."
Right there, for me, is the best definition of software architecture I have seen. Software architecture is whatever you do that allows your system to be adaptable to whatever changes its environments throws at it (scale, hardware failure, legal changes, change of business model, new forms of distribution etc.), better yet Darwin goes to to say
"In the long history of humankind (and animal kind, too) those who learned to collaborate and improvise most effectively have prevailed."
So in his view the keys to adaptability are collaboration and improvisation, which I'd translate it into modern systems as "Communication" and "Experimentation". Communication is THE key to collaboration and a quality lacking in a large number of leading engineer/architects. The core communication skill here is not about communicating what one's particular solution to a problem is, but more a style that is about inquiry, a style that illicit input and views from all significant parties and synthesize them into models and hypothesis and communicate them back and form common understanding (does your architect do that?)
Experimentation is both a personal quality and something that must built into any system as a first class architecture requirement. Experimentation is generally under-valued in architecture discussion. Systems in general have multiple views, the most popular being the 4+1-views, I would add an "Experimentation View", a view of architecture that describes which sub-systems can be experimented with and in what ways, and how would an experiment success be measured. More on "Experiment View" later, but for, I am even more convinced that analogies with and inspiration from biological systems is worthy guide for designing software systems.
Sunday, December 26, 2010
Wednesday, December 22, 2010
Cannonical Use Cases for a Relying Party
I have always felt that in identity community we spend most of our time discussing identity providers and their concerns (such as token format, protocol etc.) and do not spend enough time on and attention to relying parties. At eBay we play both roles i.e. we are both an identity provider (we provide sellers' identity and attributes to 3rd party developers) and relying party (accepting identities provisioned outside eBay marketplaces as eBay users). I can say that building a architecturally sound relying party is as challenging as building an identity provider.
In this post I simply want to enumerate the major use cases that any major relying party (that is anyone that for example plans to accept Facebook Connect) has to account for. I used the qualifier "major" to denote that these use cases are important if a given relying party has millions of uses and many services and applications (much like eBay does).
The list of use case are:
1-Sign-In and out
2-Connect and Reception
3-Link/Unlink
4-Profile Access Extension
5-Role Elevation
6-Recovery
7-Disconnect
8-Force Authentication
9-Customer Support
10-Capturing Alternative/Second Secret
and here is the descriptions:
1-Sign-In and out: This includes changes to your standard sign-in page to make it a "federated sign-in" page. The challenge here is mostly user experience i.e. how to design the UI correctly to achieve two goals:
- Not confuse existing users who will not sign up with external IDP
- Communicate to the user of external IDP what they need to do (without creating the NASCAR problem)
There are also techniques for detecting the IDPs that user may have an account with and to show a "smart" list of IDPs
2-Connect and Reception: Once users clicks on "Connect" button (if you are using connect style IDPs such as FB) or entered her OpenId URI (although this is unlikely to be adopted by users), the user is send to IDPs to sign-in and given consent to his/her information to be send to you site - let's refer to this process as Connect - then user is sent back to your site to a page/application that we refer to as "Reception". This is the processes that greets the users for the first time and provision an account in RP for him/her. I use the word "reception" to make it distinct from "registration" which is when provision is done based on data collected by RP itself. The reception process is significant b/c it covers the gap between data received from IDP and what is needed for a user to be provisioned, also it assigns the roles for new user. These roles are typically minimal since data coming from external IDPs are normally not trusted or verified. Also during reception token received from external IDP together with associated meta data is stored in a central location accessible to different functional units (application) of RP
3-Link/Unlink: Another use case (often part of reception) is to detect whether the user connecting to RP is one who already has an account. The detection can be done based on mapping the data received from IDPs to existing account, the simplest form is to check whether email addressed returned by IDP already exists.Once an account is detected, user has to prove s/he actually owns it (normally by providing password) and the accounts are link. Since architecture hygiene calls for symmetric operation, you should also allow for unlinking of accounts.
4-Profile Access Extension: RP obtain a token during reception (such as OAuth token that comes with FB Connect), this token stores a set of access permissions to user resources (perhaps hosted by IDP). Any large RP has a set of applications that will use this token (for example MyeBay application as well as eBay Search Application) it is likely that one of these applications requires more information/access privileges that user originally consented to, in these case RPs should provide a central capabilities that conduct the process of requesting, receiving extended permissions from user and updating token meta information associated with user
5-Role Elevation: The first time users connect to RP they are granted a certain role (roles), normally this is a basic role since data provided by most IDPs are not reliable (eBay as an IDP does provides verified reliable data), at some point during the user's life cycle, users needs to perform an action that requires higher role assignment, in this cases RPs should provide capabilities to assign users higher role, this normally requires users to enter more information or go thru verification. This processes produce more attributes that will become part of users profile at RP.
6-Recovery: Every RP always has to establish a method for externally provisioned identities to authenticate WITHOUT the presence of external IDP. What does this mean? suppose you accept FB Connect and FB is down for 6 hours (an event that recently happened), further imagine that you operate a site that every minute of users not being able to login means financial loss. What do you do in this scenario? You may say, this is easy, ask users to enter a password during the first time reception, but wouldn't this defeat the whole purpose (or a big part of it) of users not having to remember many passwords?
7-Disconnect: All RPs must provide the capability for a user to "disconnect" i.e. close the account that was created based on an identity provided by external IDP. I personally believe that user owns his/her data and if user wants to disconnect and remove all of his/her activities from the record. s/he should be able to (to the extent that is legal)
8-Force Authentication: This is actually a capability of IDP, but RPs need to use this when they require user to be authenticated regardless of session's authentication state as seen by IDP. For certain operation RPs require a fresh session (or session that started in the past N minutes), in this cases RPs should request a forced authentication (I am using SAML terminology here) from IDP.
In this post I simply want to enumerate the major use cases that any major relying party (that is anyone that for example plans to accept Facebook Connect) has to account for. I used the qualifier "major" to denote that these use cases are important if a given relying party has millions of uses and many services and applications (much like eBay does).
The list of use case are:
1-Sign-In and out
2-Connect and Reception
3-Link/Unlink
4-Profile Access Extension
5-Role Elevation
6-Recovery
7-Disconnect
8-Force Authentication
9-Customer Support
10-Capturing Alternative/Second Secret
and here is the descriptions:
1-Sign-In and out: This includes changes to your standard sign-in page to make it a "federated sign-in" page. The challenge here is mostly user experience i.e. how to design the UI correctly to achieve two goals:
- Not confuse existing users who will not sign up with external IDP
- Communicate to the user of external IDP what they need to do (without creating the NASCAR problem)
There are also techniques for detecting the IDPs that user may have an account with and to show a "smart" list of IDPs
2-Connect and Reception: Once users clicks on "Connect" button (if you are using connect style IDPs such as FB) or entered her OpenId URI (although this is unlikely to be adopted by users), the user is send to IDPs to sign-in and given consent to his/her information to be send to you site - let's refer to this process as Connect - then user is sent back to your site to a page/application that we refer to as "Reception". This is the processes that greets the users for the first time and provision an account in RP for him/her. I use the word "reception" to make it distinct from "registration" which is when provision is done based on data collected by RP itself. The reception process is significant b/c it covers the gap between data received from IDP and what is needed for a user to be provisioned, also it assigns the roles for new user. These roles are typically minimal since data coming from external IDPs are normally not trusted or verified. Also during reception token received from external IDP together with associated meta data is stored in a central location accessible to different functional units (application) of RP
3-Link/Unlink: Another use case (often part of reception) is to detect whether the user connecting to RP is one who already has an account. The detection can be done based on mapping the data received from IDPs to existing account, the simplest form is to check whether email addressed returned by IDP already exists.Once an account is detected, user has to prove s/he actually owns it (normally by providing password) and the accounts are link. Since architecture hygiene calls for symmetric operation, you should also allow for unlinking of accounts.
4-Profile Access Extension: RP obtain a token during reception (such as OAuth token that comes with FB Connect), this token stores a set of access permissions to user resources (perhaps hosted by IDP). Any large RP has a set of applications that will use this token (for example MyeBay application as well as eBay Search Application) it is likely that one of these applications requires more information/access privileges that user originally consented to, in these case RPs should provide a central capabilities that conduct the process of requesting, receiving extended permissions from user and updating token meta information associated with user
5-Role Elevation: The first time users connect to RP they are granted a certain role (roles), normally this is a basic role since data provided by most IDPs are not reliable (eBay as an IDP does provides verified reliable data), at some point during the user's life cycle, users needs to perform an action that requires higher role assignment, in this cases RPs should provide capabilities to assign users higher role, this normally requires users to enter more information or go thru verification. This processes produce more attributes that will become part of users profile at RP.
6-Recovery: Every RP always has to establish a method for externally provisioned identities to authenticate WITHOUT the presence of external IDP. What does this mean? suppose you accept FB Connect and FB is down for 6 hours (an event that recently happened), further imagine that you operate a site that every minute of users not being able to login means financial loss. What do you do in this scenario? You may say, this is easy, ask users to enter a password during the first time reception, but wouldn't this defeat the whole purpose (or a big part of it) of users not having to remember many passwords?
7-Disconnect: All RPs must provide the capability for a user to "disconnect" i.e. close the account that was created based on an identity provided by external IDP. I personally believe that user owns his/her data and if user wants to disconnect and remove all of his/her activities from the record. s/he should be able to (to the extent that is legal)
8-Force Authentication: This is actually a capability of IDP, but RPs need to use this when they require user to be authenticated regardless of session's authentication state as seen by IDP. For certain operation RPs require a fresh session (or session that started in the past N minutes), in this cases RPs should request a forced authentication (I am using SAML terminology here) from IDP.
Monday, December 6, 2010
OAuth protocol and "Emdedded Browser" : Illustration of a simple security decision making framework
The discussion about whether to use an embedded browser or a full browser while performing OAuth protocol ,although passionate, is nothing new. Instead of expressing a position (I am for a full browser for the record), I want to use this case to illustrate a simple framework I use to make security design/implementation decision.

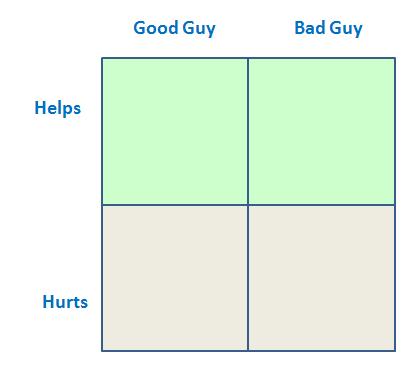
For every question/decision we designate one engineer as "good guy" and one engineer as "bad guy" and we ask each how this decision help or hurt you. I emphasis that it is critical to think and view a decision from a bad guy point of view. Most of us are basically not fraudsters and think in terms of "getting things done" and "being helpful", we rarely look at a feature and think to ourselves "How can I abuse it" (if you do, please contact me, I may have a job for you), so we assign an engineer just to do that.
Of course we want all our decision to be just as shown in the figure above :Help good guys and hurt bad guys. But that is not always the case, take using the embedded browser (and not a full pop up) to perform OAuth. This decision looks more like this:
 It helps good guys (by not having every app render a login panel, perform authentication and deal with errors etc.), but it also helps bad guys (as illustrated nicely by my friend and colleague Yitao Yao here - facebook is only one example) by making phishing easier. (it is worth pointing out that having application capture user secrets directly is along the counter diagonal in matrix above: hurts good guys and helps bad guys)
It helps good guys (by not having every app render a login panel, perform authentication and deal with errors etc.), but it also helps bad guys (as illustrated nicely by my friend and colleague Yitao Yao here - facebook is only one example) by making phishing easier. (it is worth pointing out that having application capture user secrets directly is along the counter diagonal in matrix above: hurts good guys and helps bad guys)
Does this mean you should never do this? I wish there was a simple and universal answer, but there is not.
In general you should not use embedded browser unless there is a good reason and more importantly the decision maker is fully aware of the risk (at least seen the matrix above and know the bad guys will benefit). Mitigating circumstances could be unattractive economy of fraud (your application is not a prime target fraudsters), you believe fraudsters can not effectively distribute their application to a large enough group of people, your user base is exceptionally savvy (I envy you) or your mobile operator has a good control over nature of applications and what they do (think Apple-like).

For every question/decision we designate one engineer as "good guy" and one engineer as "bad guy" and we ask each how this decision help or hurt you. I emphasis that it is critical to think and view a decision from a bad guy point of view. Most of us are basically not fraudsters and think in terms of "getting things done" and "being helpful", we rarely look at a feature and think to ourselves "How can I abuse it" (if you do, please contact me, I may have a job for you), so we assign an engineer just to do that.
Of course we want all our decision to be just as shown in the figure above :Help good guys and hurt bad guys. But that is not always the case, take using the embedded browser (and not a full pop up) to perform OAuth. This decision looks more like this:
Does this mean you should never do this? I wish there was a simple and universal answer, but there is not.
In general you should not use embedded browser unless there is a good reason and more importantly the decision maker is fully aware of the risk (at least seen the matrix above and know the bad guys will benefit). Mitigating circumstances could be unattractive economy of fraud (your application is not a prime target fraudsters), you believe fraudsters can not effectively distribute their application to a large enough group of people, your user base is exceptionally savvy (I envy you) or your mobile operator has a good control over nature of applications and what they do (think Apple-like).
Sunday, December 5, 2010
Kitchen Meeting
I started an experimentation a few weeks back. Instead of scheduling and holding a meeting in one of eBay's formal meeting rooms, I tried to meet with people in kitchen or cafe (or starbucks across the street from the Hamilton campus) - now this is partly b/c it is getting too tough to find a free room, but I also had a hypothesis that when people meet in informal setting - specially a place that has to do with eating - they are more likely to collaborate.
I have to say the results are mixed so far, on one hand it indeed does make a difference, people seem to be friendlier and more willing to see "the other side" of issue - whatever it might be. However I also noticed that they are more likely to "forget" or back-off from agreements or conclusions that were reached too.
For now I keep doing this as much as I can, at least it gives me an incentive to keep the number of people in a meeting to 3 people max, this alone helps increase the effectiveness of meetings.
I have to say the results are mixed so far, on one hand it indeed does make a difference, people seem to be friendlier and more willing to see "the other side" of issue - whatever it might be. However I also noticed that they are more likely to "forget" or back-off from agreements or conclusions that were reached too.
For now I keep doing this as much as I can, at least it gives me an incentive to keep the number of people in a meeting to 3 people max, this alone helps increase the effectiveness of meetings.
Wednesday, October 27, 2010
PayPal Identity Services Talk @ PayPal Innovate 2010
Today at the PayPal Developers conference Ashish Jain, my friend and colleague and PayPal’s point man on all things identity, talked about PayPal vision of identity and PayPal Identity Service in his presentation titled, not surprisingly, “PayPal Identity Services”.
If you are involved in the world of internet, as a developer or even an observer, or if you have attended any web related conference in the past 12-18 month (including our own DevCon) you must be familiar with the core identity problem: users have too many accounts, too many password, too often they forget them, it is too easy to phish passwords and too expensive for companies to support users who either forgot their passwords or have had their account taken over …. Ashish talked about it in his presentation (as it is mandatory for these presentations, including mine, to recount the carnage first).
You may have guessed the next step, PayPal, among many others, offers to be an Identity Provider (IDP). Your one and only account you ever need (at least for whenever you want to shop on the Internet).
You may think, so what? There are so many other identity providers (most notably Facebook) … but (as Lee Corso of ESPN says) “not so fast my friend”, there is actually a difference in this game of being identity provider between PayPal and everyone else, what Ashish, modestly, calls “Qualified Data” (interestingly the second bullet point in his slide – why not the first? I have to ask him).
See, as it turns out providing identity (as in what an IDP does) it is not that hard, pick a protocol (OpenID, OAuth, SAML …) and transfer identity data (unique identifier, name, email, phone number etc.) from the IDP to Relying Party (RP). You can do that in few hours (literally), what turns out to be hard (and expensive and complex), is providing “High Quality” identity, as in identity data the someone actually validates and make sure they are accurate and up to date and actually owned by the person who claims s/he owns it. This is what Ashish means by “Qualified Data”. Now if you are a merchant, which identity you rather rely on? An identity from a site that simply takes users claims (about what her name is, where she lives etc.) and toss it over to you or from PayPal where this set of data is verified and maintained and by the way you know that there is a valid financial/payment instrument attached to it?
Too often people responsible for building an identity provider argue endlessly about merits of protocols, compare OpenID to OAuth and talk about how complex SAML is. In the process they miss the much bigger point: what matters is the quality of identity provided not the means by which it is provided.
This is what make PayPal identity (regardless of whether they use OpenID or OAuth or anything else) potentially the most interesting and useful identity in my view.
Ashish also shows a demo where PayPal OpenID service is wrap by Gigya API. Gigya is an aggregator of identity provider, instead of learning multiple APIs from different IDPs, developers simply deal with Gigya API. It is an interesting concept. Check them out here.
It would be interesting to see how far PayPal push their Identity Service (both in terms of end user adoption and merchant adoption) and whether or not they offer different classes of identity (based on data quality) and respective financial assurance levels.
Wednesday, October 13, 2010
My old blog post on PayPal Platform
I found this old blog that I posted after 'Next Gen PayPal Platform" in eBay DevCon 2009. I am adding here for the record and also b/c the format of the session and the ideas that were generated was very interesting.
Looking back, you can also track which ideas PayPal actually implemented ...
Looking back, you can also track which ideas PayPal actually implemented ...
Thursday, October 7, 2010
MongoDB is Web scale ...
This is a funny clip - produced by the xtranormal technolog - courtesy my friend Gunnar Peterson. It pokes fun at people jumping on No SQL and MongoDB bandwagon. I have to say I can relate to the sentiment, No SQL, KV storages etc. are suited for certain use cases and access pattern, but a vast majority of day to day use cases can be handled just fine with SQL.Even if you are Mongo fan it is fun to watch this.
- Warning: The clip uses adult language.
- Warning: The clip uses adult language.
Wednesday, September 22, 2010
Login Failed, Try Again: 10 Best Practices for Authentication in the Cloud
Here is the deck for my presentation at 2010 JavaOne. It summarizes our experience and leanings in creating an identity foundation for eBay application platform (AP). In retrospect a lot of the lessons seems like "Motherhood and apple pie" but I suppose there is knowing and then there is understanding. Also what I have seen is that in general there is not a deep understanding (or even awareness) of identity architecture as a first class enterprise infrastructure among enterprise architect and software engineers.
Anyway, the deck is designed to be talked over, so simply reading it may not be as interesting.
Anyway, the deck is designed to be talked over, so simply reading it may not be as interesting.
Monday, September 20, 2010
LSE economist answers: "Why are terrorists often engineers?
IEEE Spectrum has an interesting podcast here title Why are terrorists often engineers.
Basically two hypothesis:
- Engineers are smart and high potential people and when/if they don't find ample employment opportunities they become frustrated
- Engineers have orientations toward hierarchy and order that is also a common theme with fundamentalism.
Also interesting (according to the LSE researchers) engineers are more religious and right leaning compare to others - one wouldn't guess that living in the Bay Area.
Basically two hypothesis:
- Engineers are smart and high potential people and when/if they don't find ample employment opportunities they become frustrated
- Engineers have orientations toward hierarchy and order that is also a common theme with fundamentalism.
Also interesting (according to the LSE researchers) engineers are more religious and right leaning compare to others - one wouldn't guess that living in the Bay Area.
Sunday, September 19, 2010
JaveOne 2010 Talk
Latest details I received from conference organizers today (it is kind of late, isn't it?) about time and location of my talk @ JavaOne:
ID# : S314414
Title : Login Failed, Try Again: 10 Best Practices for Authentication in the Cloud
Track: Enterprise Service Architectures and the Cloud
Date : 23-SEP-10
Time : 14:00 - 15:00
Venue: Parc 55
Room : Cyril Magnin I
ID# : S314414
Title : Login Failed, Try Again: 10 Best Practices for Authentication in the Cloud
Track: Enterprise Service Architectures and the Cloud
Date : 23-SEP-10
Time : 14:00 - 15:00
Venue: Parc 55
Room : Cyril Magnin I
what is a "Platform"?
Usually the answer to the question “What is X”, at least in the context of software engineering, is given in two different ways:
- What does X do or what is X supposed to d.
- How does X work.
The former is more of philosophical answer and the latter more of a pragmatic one. For example, “what is a service?” could be answered in one the two ways:
- A unit of functionality that is exposed thru a well defined interface and is loosely coupled to its consumers, it is autonomous, reusable, discoverable and stateless.
Or it can be answered as
- It is a unit of code exposed thru a WSDL and invoked using SOAP and it is language neutral
Those who know me know that I am more inclined toward philosophy. So when I attempt to answer “what is a platform?” – as I had to recently when we were building eBay Application Platform - I opt for what it does.
To me the answer is simple, at least in the realm of software engineering:
A software platform is any set of functionality that increases developers’ productivity, plain and simple.
Operating systems do that, languages do that, APIs do that so do IDEs such as Eclipse. So what is the difference between tools and platforms? Tools are not programmable, platforms are. In other words developers can “program” platforms to suit their needs. In other words tools are used to accomplish one task, platforms can be used (i.e. programmed) to perform different tasks. Some platforms start as tools (like Eclipse, Excel) but evolve to become a platform.
Why, besides philosophical clarity, is this important? It can be used to define a clear goal and metrics for success of whatever is called a “Platform”.
- What does X do or what is X supposed to d.
- How does X work.
The former is more of philosophical answer and the latter more of a pragmatic one. For example, “what is a service?” could be answered in one the two ways:
- A unit of functionality that is exposed thru a well defined interface and is loosely coupled to its consumers, it is autonomous, reusable, discoverable and stateless.
Or it can be answered as
- It is a unit of code exposed thru a WSDL and invoked using SOAP and it is language neutral
Those who know me know that I am more inclined toward philosophy. So when I attempt to answer “what is a platform?” – as I had to recently when we were building eBay Application Platform - I opt for what it does.
To me the answer is simple, at least in the realm of software engineering:
A software platform is any set of functionality that increases developers’ productivity, plain and simple.
Operating systems do that, languages do that, APIs do that so do IDEs such as Eclipse. So what is the difference between tools and platforms? Tools are not programmable, platforms are. In other words developers can “program” platforms to suit their needs. In other words tools are used to accomplish one task, platforms can be used (i.e. programmed) to perform different tasks. Some platforms start as tools (like Eclipse, Excel) but evolve to become a platform.
Why, besides philosophical clarity, is this important? It can be used to define a clear goal and metrics for success of whatever is called a “Platform”.
Tuesday, September 7, 2010
Authorization: One Step At a Time
In my experience authorization (much like identity and authentication) is a poorly understood topic by most engineers, architects and product managers. The prevailing narrative about authorization is magic box protecting a resource that knows every policy applicable to a resource and how to correctly enforce them, or at least know who can access the resources and in what way.
Both of these views are inaccurate (or partially true) and often lead to construction of single layer, complex to implement and impossible to manage systems.Authorization by nature is a hierarchical filtering mechanism; the operating keyword by far is hierarchical. The successful authorization systems are the ones that consist of several collaborating layers of authorization and filtering, each layer controls one dimension of access.
For example, imagine a company with a few departments: Executives, Marketing, Accounting, Sales and Product Development. Further imagine that each department has resources (data and services that operate on data) and applications (software users use to access services, view and manipulate data). In particular accounting has three applications: a data entry application, reporting application and a full book management application (web based or native app does not matter here). Here are the logical authorization rules expressed as typical requirement statements:
1. No person or application in marketing can access any resources in accounting
2. Data entry application cannot access account payable, any payment services or reporting services
3. Reporting applications cannot make any changes (write, edit) data
4. Full Book Management application can perform any function
5. Only Accounting manager can pay an invoice greater than $1000
6. Only CFO can run quarterly profit and loss reports.
Do you see the hierarchy here? Can you translate it to AuthZ system hierarchy?

Rule (1) talks about a large granularity “department”, rules 2,3,4 talk about applications and rule 5,6 talk about roles within a particular application or set of apps.
The first rule should be enforced thru a router or a gateway that blocks access to any application from marketing department. That is an effective isolation mechanism implement an authorization rule.
Second set of rules (2,3,4) should be enforced via a system level guard that only operate in request headers and tokens binded to them. Examples of such systems are ESB or pipeline style authorization handlers.
The last set of rules 5,6 should be enforced with an application level authorization system or guard that is aware of different roles within an application and their privileges vis-à-vis resources.
Now what happens if you collapsed three systems into one? Well in short the authorization system becomes complex to implement and tough to manage and three different layers with three different velocity of change would become one constantly changing piece of code.
The authorization system must scan everything in request, from originating IP address, to headers identifying calling application to payload determining parameters of operations. It has to understand a wide range of concerns from deployment (impacting IP addresses) to business logic ($1000 limit).
Authorization is tough but single layer authorizations systems like this are nightmares of manageability.
Imagine what would have happened if all checks at the airports (from entry to the terminal till when you sit in your seat inside the plane) would have been performed by the security officer upfront who today only checks your driver license and matches that with your ticket? At the airport there is three different levels: The guys who check your driver license and ticket, the TSA guys who check your bags and the crew at the gate who check your ticket and make sure you don’t sit in first class.
Both of these views are inaccurate (or partially true) and often lead to construction of single layer, complex to implement and impossible to manage systems.Authorization by nature is a hierarchical filtering mechanism; the operating keyword by far is hierarchical. The successful authorization systems are the ones that consist of several collaborating layers of authorization and filtering, each layer controls one dimension of access.
For example, imagine a company with a few departments: Executives, Marketing, Accounting, Sales and Product Development. Further imagine that each department has resources (data and services that operate on data) and applications (software users use to access services, view and manipulate data). In particular accounting has three applications: a data entry application, reporting application and a full book management application (web based or native app does not matter here). Here are the logical authorization rules expressed as typical requirement statements:
1. No person or application in marketing can access any resources in accounting
2. Data entry application cannot access account payable, any payment services or reporting services
3. Reporting applications cannot make any changes (write, edit) data
4. Full Book Management application can perform any function
5. Only Accounting manager can pay an invoice greater than $1000
6. Only CFO can run quarterly profit and loss reports.
Do you see the hierarchy here? Can you translate it to AuthZ system hierarchy?

Rule (1) talks about a large granularity “department”, rules 2,3,4 talk about applications and rule 5,6 talk about roles within a particular application or set of apps.
The first rule should be enforced thru a router or a gateway that blocks access to any application from marketing department. That is an effective isolation mechanism implement an authorization rule.
Second set of rules (2,3,4) should be enforced via a system level guard that only operate in request headers and tokens binded to them. Examples of such systems are ESB or pipeline style authorization handlers.
The last set of rules 5,6 should be enforced with an application level authorization system or guard that is aware of different roles within an application and their privileges vis-à-vis resources.
Now what happens if you collapsed three systems into one? Well in short the authorization system becomes complex to implement and tough to manage and three different layers with three different velocity of change would become one constantly changing piece of code.
The authorization system must scan everything in request, from originating IP address, to headers identifying calling application to payload determining parameters of operations. It has to understand a wide range of concerns from deployment (impacting IP addresses) to business logic ($1000 limit).
Authorization is tough but single layer authorizations systems like this are nightmares of manageability.
Imagine what would have happened if all checks at the airports (from entry to the terminal till when you sit in your seat inside the plane) would have been performed by the security officer upfront who today only checks your driver license and matches that with your ticket? At the airport there is three different levels: The guys who check your driver license and ticket, the TSA guys who check your bags and the crew at the gate who check your ticket and make sure you don’t sit in first class.
Sunday, August 8, 2010
CAP Therom and Digital Identity
If you read this blog chances are you are familier with the CAP theorem, it basically states that any distributed system operating at scale can choose at most two of the followings three:
- Consistency
- Availability
- Partition Tolerance
There other examples of pick any "2 out of 3" in life are:
- The management rule of thumb: Good, Cheap, Fast
- Graduate student dilemma: Fun, Grades, Sleep (replace fun with your own idea of it)
- Investment advice: Low Risk, High Return, Legality - if you pick low risk and high return chances are you are compromising legality :-)
They way I look at all these "rules" is that the space of each of these domains offer only two degrees are freedom and once you choose two points (that effectively determine or fix your degree of freedom, the third point will be chosen for you)
For example in "Good, Cheap, Fast", your degrees of freedom are basically time and money, once you choose how much time and money you want to spend all three qualities are determined. So now, if you choose time and money not directly, but indirectly via the choice of say good and fast, you automatically also chosen "not cheap".
Interestingly digital identity offers the same 2 out of 3 dynamics among the three main attributes of
- Quality of Identity
- Usability
- Cost
"Quality of Identity" is a measure of how uniquely a set of data represents a real world person and how strongly an IDP stands behind such assertion (for example whether IDP guarantees up to a certain amount damages resulting from inaccurate data), usability is how easy it is for IDP to provision such identities.
It is clear that if an IDP chooses to provide high quality identity and also wants to makes its provisioning easy to use (or scalable for that matter), it has to spend a lot of money.
In practice though, IDPs segment the user base and only provide high quality identity for users to whom maximum credit are extended (e.g. users who can sell the most on eBay).
- Consistency
- Availability
- Partition Tolerance
There other examples of pick any "2 out of 3" in life are:
- The management rule of thumb: Good, Cheap, Fast
- Graduate student dilemma: Fun, Grades, Sleep (replace fun with your own idea of it)
- Investment advice: Low Risk, High Return, Legality - if you pick low risk and high return chances are you are compromising legality :-)
They way I look at all these "rules" is that the space of each of these domains offer only two degrees are freedom and once you choose two points (that effectively determine or fix your degree of freedom, the third point will be chosen for you)
For example in "Good, Cheap, Fast", your degrees of freedom are basically time and money, once you choose how much time and money you want to spend all three qualities are determined. So now, if you choose time and money not directly, but indirectly via the choice of say good and fast, you automatically also chosen "not cheap".
Interestingly digital identity offers the same 2 out of 3 dynamics among the three main attributes of
- Quality of Identity
- Usability
- Cost
"Quality of Identity" is a measure of how uniquely a set of data represents a real world person and how strongly an IDP stands behind such assertion (for example whether IDP guarantees up to a certain amount damages resulting from inaccurate data), usability is how easy it is for IDP to provision such identities.
It is clear that if an IDP chooses to provide high quality identity and also wants to makes its provisioning easy to use (or scalable for that matter), it has to spend a lot of money.
In practice though, IDPs segment the user base and only provide high quality identity for users to whom maximum credit are extended (e.g. users who can sell the most on eBay).
Monday, July 12, 2010
Enole - A New Identity Linking Startup
The other day, via Venture Beat, I learn about a new start up called Enole. Since the company is in Identity domain I was naturally interested and start looking around. The idea is as interesting as it is old: to unify all identities online and offline and to carry it with you with your cell phone. (use your fav search engine to look for products, ideas and patent on storing all sorts of identity information on cell phones ranging from credit card to login name and passwords to codes that unlock cars and doors etc.)
However it is often not the novelty of an idea that sets a company apart but the strength in execution and market strategy. So with a bit of healthy skepticism I looked at the site.
There is the usual marketing and hype in the web site – which I completely understand. Beyond the hype Enole is a service that allows a developer/application (identified by a pre-issued token) to link up a user and a device. A user simply means an identifier string (email or any other string). So effectively there is a link among three entities Application that creates a link, user and device.
The rest of the API is about the basic create, update, query of link, users and devices. However there a few key questions that are not answered in the documentation:
- Can an application that has not created a user or device query them?
- How does the system deals with duplicate email addresses and identifiers across multiple applications?
- If another application picks up my devices unique id, can they query Enole DB? If they can and get my information, do I need to authorize (OAuth style) the
information before application can use it?
- How would a user remove his/her account.
- How the "sign-up" tokens are stored and what happens if they are compromised
In essence, the API document describes the CRUD operation of user, device and link entity but does not describe a formal authentication protocol between users, devices etc. As such it can not really be evaluated in details.
Additionally, it is not very clear how end users (not developers) are in control of their own identity and information. This is really big for any company that has ambitions in the identity area.
Also, if you have been reading my blog regularly you know that I give a LOT of significance to the language and terminology one uses to describe either her problem or solution. The language used in Enole site is not that of identity, authentication or communication protocol domains. This, to me, is not the most positive sign.
Having said that, I think Enole is an early stage start up and like any other early stage start up their original idea will evolve, I will keep an eye them to see how they evolve and how their technology be used.
However it is often not the novelty of an idea that sets a company apart but the strength in execution and market strategy. So with a bit of healthy skepticism I looked at the site.
There is the usual marketing and hype in the web site – which I completely understand. Beyond the hype Enole is a service that allows a developer/application (identified by a pre-issued token) to link up a user and a device. A user simply means an identifier string (email or any other string). So effectively there is a link among three entities Application that creates a link, user and device.
The rest of the API is about the basic create, update, query of link, users and devices. However there a few key questions that are not answered in the documentation:
- Can an application that has not created a user or device query them?
- How does the system deals with duplicate email addresses and identifiers across multiple applications?
- If another application picks up my devices unique id, can they query Enole DB? If they can and get my information, do I need to authorize (OAuth style) the
information before application can use it?
- How would a user remove his/her account.
- How the "sign-up" tokens are stored and what happens if they are compromised
In essence, the API document describes the CRUD operation of user, device and link entity but does not describe a formal authentication protocol between users, devices etc. As such it can not really be evaluated in details.
Additionally, it is not very clear how end users (not developers) are in control of their own identity and information. This is really big for any company that has ambitions in the identity area.
Also, if you have been reading my blog regularly you know that I give a LOT of significance to the language and terminology one uses to describe either her problem or solution. The language used in Enole site is not that of identity, authentication or communication protocol domains. This, to me, is not the most positive sign.
Having said that, I think Enole is an early stage start up and like any other early stage start up their original idea will evolve, I will keep an eye them to see how they evolve and how their technology be used.
Saturday, July 3, 2010
Recall and Precision: It is not how many bad guys you caught, it is how many good guys suffered
The measurement of "Recall and Precision" is front and center in all of our fraud prevention measures and algorithms, you can read a general description of this concept and the mathematical definition in Wikipedia, but I have had better luck explaining the concept with this example:
Imagine there is a band of armed rubbers (say 5 guys) in your town and you sent your best cops to round them up. After a day they come back arresting a group of men. How do know if they did a good job?
The obvious answer is whether they have arrested ALL the gang members. So the measurement is "how many gang members have they arrested?" in this regard 5 is better than 4 and 4 is better than 3. Simple
But is that enough? Let's imagine three out comes
1 - The cops came back having arrested 5 guys, all of them gang member. This is perfect, they arrested ALL the RIGHT people, and ZERO WRONG person, recall = Precision = 100%.
2 - The cops came back having arrested 10 guys, 5 gang members of 5 random and innocent guys. In this case recall=100% but precision is 50% - which in this case is clearly not acceptable (even worse they could have arrested all men in the community, recall still would be 100% but precision would be near zero - that is called Carpet Bombing)
3- The cops came back with 3 guys, all gang member, no innocent guys was arrested. In this case recall= 60% but precision=100% - this is called Proof Beyond the Reasonable Doubt i.e. a philosophy of design whereby it is better to let a bad guy go free then to harm a good guy.
In modeling risk and fraud and designing algorithms to prevent them, we always have to measure the algorithm based on their recall and precision. Low precision methods typically cost a lot in term of customer support and friction in user experience, low recall algorithms and method result in higher losses for the company.
in designing a Risk Management strategy, I tend to side with lower recall then lower precision and then manage the ratio of loss/revenue with the higher revenue generated by higher precision - or right customer who were let in.
What if the cops came back with 10 guys, 5 are gang members and 5 are innocent? in this case they arrested all gang members (100% catch rate or 100% recall) but
Imagine there is a band of armed rubbers (say 5 guys) in your town and you sent your best cops to round them up. After a day they come back arresting a group of men. How do know if they did a good job?
The obvious answer is whether they have arrested ALL the gang members. So the measurement is "how many gang members have they arrested?" in this regard 5 is better than 4 and 4 is better than 3. Simple
But is that enough? Let's imagine three out comes
1 - The cops came back having arrested 5 guys, all of them gang member. This is perfect, they arrested ALL the RIGHT people, and ZERO WRONG person, recall = Precision = 100%.
2 - The cops came back having arrested 10 guys, 5 gang members of 5 random and innocent guys. In this case recall=100% but precision is 50% - which in this case is clearly not acceptable (even worse they could have arrested all men in the community, recall still would be 100% but precision would be near zero - that is called Carpet Bombing)
3- The cops came back with 3 guys, all gang member, no innocent guys was arrested. In this case recall= 60% but precision=100% - this is called Proof Beyond the Reasonable Doubt i.e. a philosophy of design whereby it is better to let a bad guy go free then to harm a good guy.
In modeling risk and fraud and designing algorithms to prevent them, we always have to measure the algorithm based on their recall and precision. Low precision methods typically cost a lot in term of customer support and friction in user experience, low recall algorithms and method result in higher losses for the company.
in designing a Risk Management strategy, I tend to side with lower recall then lower precision and then manage the ratio of loss/revenue with the higher revenue generated by higher precision - or right customer who were let in.
What if the cops came back with 10 guys, 5 are gang members and 5 are innocent? in this case they arrested all gang members (100% catch rate or 100% recall) but
Friday, June 25, 2010
Special Forces, Regular Army and Start ups
From time to time I advise start ups on mostly technical matters, inevitably they ask me for referrals to hire engineers or help with editing their job postings.
Typically they email me a very detailed and specific job description for a, say, Data Architect or Ajax messaging programmer or Java Engineer complete with an obscure list of libraries and technologies that the candidate expected to be master in (probably those technologies were suggested by their VC to them in their last meeting)
Start ups should be built like special forces, with a few brave and smart generalists with a lot of heart and "get it done" attitude, not by deep specialists in any certain area - I am talking about the first few engineers here - a statistical modeler with no programming skills or a Data Architect with focus on data replication makes a fine contractor for a short time to advise your core engineering team, but should not be one the first 5 engineers you hire.
Typically they email me a very detailed and specific job description for a, say, Data Architect or Ajax messaging programmer or Java Engineer complete with an obscure list of libraries and technologies that the candidate expected to be master in (probably those technologies were suggested by their VC to them in their last meeting)
Start ups should be built like special forces, with a few brave and smart generalists with a lot of heart and "get it done" attitude, not by deep specialists in any certain area - I am talking about the first few engineers here - a statistical modeler with no programming skills or a Data Architect with focus on data replication makes a fine contractor for a short time to advise your core engineering team, but should not be one the first 5 engineers you hire.
Wanna Make Your Life Hard? There is an app for that, or maybe 100,000
These days it is not uncommon to find some one with 100+ apps installed on his/her phone (maybe you are one of those?). I imagine most of those apps are used once or twice and will never be used, the only time you see them (or their icon) is when you scroll past by them to get to your 2 or 3 (or five) apps you actually use frequently.
This app mania clutters UIs and waste a lot time, and I can't help but thinking "do we simply forget all the lessons and progress of last 10-15 years simply because a device came along with attractive aesthetics?"
What happened to "browser is the operating system?" in the days that most desktop apps are moving to cloud and being delivered thru browsers, why is it that most (if not all) mobile apps are native code? Yes native apps still have certain capability that browsers do not offer YET, but with HTML 5 and Web Kit (and maybe with a little bit of industry support to close the remaining gaps) browser based apps would be sufficient for large majority of mobile apps.
Don't get me wrong, there will always be need for native apps, but much like with desktop, over time only a few apps will be privileged to be native, most other will and should be browser based standard, write one, run on any browser apps.
This makes development of mobile apps simpler and more cost effective, instead of maintaining three apps for iPhone, Andriod and Blackberry, most developer only maintain one version, and you only install a few apps that truly need to be native apps.
This app mania clutters UIs and waste a lot time, and I can't help but thinking "do we simply forget all the lessons and progress of last 10-15 years simply because a device came along with attractive aesthetics?"
What happened to "browser is the operating system?" in the days that most desktop apps are moving to cloud and being delivered thru browsers, why is it that most (if not all) mobile apps are native code? Yes native apps still have certain capability that browsers do not offer YET, but with HTML 5 and Web Kit (and maybe with a little bit of industry support to close the remaining gaps) browser based apps would be sufficient for large majority of mobile apps.
Don't get me wrong, there will always be need for native apps, but much like with desktop, over time only a few apps will be privileged to be native, most other will and should be browser based standard, write one, run on any browser apps.
This makes development of mobile apps simpler and more cost effective, instead of maintaining three apps for iPhone, Andriod and Blackberry, most developer only maintain one version, and you only install a few apps that truly need to be native apps.
Monday, June 14, 2010
"My Dad is 50 years old, weighs 30 lbs and is 40 ft tall...I like him b/c he is silly"
A very competent and respected colleague of mine, in his early 30s, 5’9” and reasonably proportional I might add, has the following written by his 5 year old son posted in his cube:
“My dad is 50 years old, 30lbs and 40 feet tall and I like him because he is silly”
Besides it being funny and making me think what my daughters really think about me, it reminds me of how our products can be perceived and used by other engineers: They way they see it not they way “they are”.
If you are developing systems, services and products for other developers, it is important to understand that your will be used they way others understand it and not the way you planned it to be used. I have seen a session service used as a general purpose cache, ESB riddled with use-case specific routing logic, authentication service used as data pre-fetch mechanism and presentation logic (in XSL) saddled with complex and critical business logic – of course in XSL. All examples of how we all use tools to solve our problems regardless of whether or not the tool is meant for it (remember eating jelly with knife?)
The first solution of course is documentation, but here is what that documentation should include:
- Real world, working and end to end examples of the right way to use the services/product
- Examples should be cut-and-paste able (to the extent possible)
- Realistic examples of wrong way of using systems, updated periodically as new misuses surface
- Direction and pointers for how to address the original need leading to the misuse.
- Address of a user (or expert monitored) forum where users can get help
“My dad is 50 years old, 30lbs and 40 feet tall and I like him because he is silly”
Besides it being funny and making me think what my daughters really think about me, it reminds me of how our products can be perceived and used by other engineers: They way they see it not they way “they are”.
If you are developing systems, services and products for other developers, it is important to understand that your will be used they way others understand it and not the way you planned it to be used. I have seen a session service used as a general purpose cache, ESB riddled with use-case specific routing logic, authentication service used as data pre-fetch mechanism and presentation logic (in XSL) saddled with complex and critical business logic – of course in XSL. All examples of how we all use tools to solve our problems regardless of whether or not the tool is meant for it (remember eating jelly with knife?)
The first solution of course is documentation, but here is what that documentation should include:
- Real world, working and end to end examples of the right way to use the services/product
- Examples should be cut-and-paste able (to the extent possible)
- Realistic examples of wrong way of using systems, updated periodically as new misuses surface
- Direction and pointers for how to address the original need leading to the misuse.
- Address of a user (or expert monitored) forum where users can get help
Thursday, June 10, 2010
Presentation for my eBay DevCon 2010 Talk
Here is the slide deck for my talk @ eBay DevCon 2010" The User Who Came In From the Cloud.
If you ever wanted to consume identity from external identity providers (Facebook, Google, Yahoo, PayPal etc.) you may want to check it out.
If you ever wanted to consume identity from external identity providers (Facebook, Google, Yahoo, PayPal etc.) you may want to check it out.
Friday, June 4, 2010
"Failure is not fatal, but failure to change might be" John Wooden
John Wooden, the Wizard and West wood, passed away today. I imagine most of the readers of my blog probably do not know him, you can read all about him by visiting his official web site.
He was the embodiment of the word "coach", not only did he win 10 national championship (7 consecutive), he developed players and MEN.
I am a Big Ten guy and never cared much about Pac 10, but I learned about Wooden by leanring about his amazing basketball dynasty at UCLA - anyone who ever worked with young 20 year old programmers can appriciate what it takes to get them focus on a goal and develop the decipline to achive it - then I read his books and his favoriate maxims. And only then I truely appriciated why they call him "The Wizard".
Of course he was not a software architect, but what said about "...failure to change" should be on top of every architect's mind, he proved it by architecting a system that work flawlessly level in 12 different environments. How many of us can create a system that works in 12 different environments?
Yet again, make me convinced that the essence of architecture is about changing gracefully.
He was the embodiment of the word "coach", not only did he win 10 national championship (7 consecutive), he developed players and MEN.
I am a Big Ten guy and never cared much about Pac 10, but I learned about Wooden by leanring about his amazing basketball dynasty at UCLA - anyone who ever worked with young 20 year old programmers can appriciate what it takes to get them focus on a goal and develop the decipline to achive it - then I read his books and his favoriate maxims. And only then I truely appriciated why they call him "The Wizard".
Of course he was not a software architect, but what said about "...failure to change" should be on top of every architect's mind, he proved it by architecting a system that work flawlessly level in 12 different environments. How many of us can create a system that works in 12 different environments?
Yet again, make me convinced that the essence of architecture is about changing gracefully.
Saturday, May 29, 2010
eBay DevCon 2010 Talk and The Spy Who Came in from the Cold
 |  |
The title for the talk is "The User Who Came in From the Cloud". It is a play on my favoriate cold war spy novels of all time "The Spy Who Came in from the Clod", if you are into spy novel or cold war buff, I recommend reading the it.
Sunday, May 16, 2010
LinkedIn Recommendations Negatively Corelate to Performance?
I always wondered how true LinkedIn recommendations really are, it is a given that there is strong positive bias in them, after all you ask for those recommendations presumably from people that liked what you did. Still I was curious to see whether it has a correlation with performance, now, rather unscientifically, I am arriving at the conclusion that it does. but negatively !!
I interview a lot of people, due to the nature of my job I also know and work with a lot of people. These people range from junior engineers to mid-level manager and to senior executives and from smart, talented and competent to not very effective and some times down right "wrongly casted". For all my interviews and recently for people I worked with that, in my view fall into extremes of performance I looked them up in LinkedIn. The outcome was surprising: The competent people almost never had any recommendations and half the time not even a complete profile. On the other hand, the people on the less competent side of the spectrum often had glowing references from half dozen folks. Why is it? I can not be sure, but here is my guess:
The less competent people know where they fit in the performance curve, they anticipate needing to look for a job sooner than later so they make sure their affairs are in order. They ask for references more frequently and are likely to get it since, first, people are or would like to be nice and helpful, second, they expect reciprocity.
On the other hand, more competent folks either do not expect a job hunt and if they need one often get it thru their own network (either follow their bosses or other colleagues who do whatever they can to get them to join them in their new gig).
To be clear, I do not hold anyone's LinkedIn recommendations against them, I am just stating an observation over the past 18-24 months.
I interview a lot of people, due to the nature of my job I also know and work with a lot of people. These people range from junior engineers to mid-level manager and to senior executives and from smart, talented and competent to not very effective and some times down right "wrongly casted". For all my interviews and recently for people I worked with that, in my view fall into extremes of performance I looked them up in LinkedIn. The outcome was surprising: The competent people almost never had any recommendations and half the time not even a complete profile. On the other hand, the people on the less competent side of the spectrum often had glowing references from half dozen folks. Why is it? I can not be sure, but here is my guess:
The less competent people know where they fit in the performance curve, they anticipate needing to look for a job sooner than later so they make sure their affairs are in order. They ask for references more frequently and are likely to get it since, first, people are or would like to be nice and helpful, second, they expect reciprocity.
On the other hand, more competent folks either do not expect a job hunt and if they need one often get it thru their own network (either follow their bosses or other colleagues who do whatever they can to get them to join them in their new gig).
To be clear, I do not hold anyone's LinkedIn recommendations against them, I am just stating an observation over the past 18-24 months.
Thursday, April 29, 2010
Appholes!
Jon Stewart is a communication genius - as evident by the title of this post borrowed from him. He some how mastered the art of hiding behind comedy shield and turn serious when he needs it to make his point. He has become the nations moral compass of sorts. But that is a different story.
I read Jobs' Thoughts on Flash where he describes Apple's reasons for banning popular Adobe's Flash technology from Apple products. All the while thinking to myself " you got to be kidding me!".
Where are all the MSFT bashers of mid 90s and early 2000s? Half the countries in the world would have dragged MSFT to their highest court if they ever did such thing. After all MSFT didn't ban NetScape browsers, it simply made its own the default.
Back then, MSFT made the same claim as Apple does today:
"Our motivation is simple – we want to provide the most advanced and innovative platform to our developers..."
Why is there no outrage this time around in the tech world? Why the double standard?
Now, banning Flash is only one example, Apple's reaction to Gizmodo is also something that makes you wonder. Listen to Stewart version of it:
I read Jobs' Thoughts on Flash where he describes Apple's reasons for banning popular Adobe's Flash technology from Apple products. All the while thinking to myself " you got to be kidding me!".
Where are all the MSFT bashers of mid 90s and early 2000s? Half the countries in the world would have dragged MSFT to their highest court if they ever did such thing. After all MSFT didn't ban NetScape browsers, it simply made its own the default.
Back then, MSFT made the same claim as Apple does today:
"Our motivation is simple – we want to provide the most advanced and innovative platform to our developers..."
Why is there no outrage this time around in the tech world? Why the double standard?
Now, banning Flash is only one example, Apple's reaction to Gizmodo is also something that makes you wonder. Listen to Stewart version of it:
| The Daily Show With Jon Stewart | Mon - Thurs 11p / 10c | |||
| Appholes | ||||
| ||||
Wednesday, April 21, 2010
xAuth: Second Tier IDP Club
I learned today that the toolbar company Meebo today announced a proposed standard called xAuth to solve the so called NASCAR problem of OpenID.
The essence of the solution is to create a centralized database (xauth.org) where users preferred IDPs are listed. For example if you use Google Friend Connect then xauth.org DB saves that preference for you. Now the publishers/RP that you visit, make a call to xauth.org (upon your visit) and learn that you prefer to "login" using GFC and only show that logo to you instead of a dozen logos from FB, Tweeter, Yahoo, AOL, Google, Microsoft, VeriSign and whoever else who jumps on federated ID band wagon.
My initial reaction (emphasis on initial) is "Are you serious?" and "Is it opt-in or opt-out" (apparently it is opt-out).
Two comments:
1- Of course collecting all people's information in one central database make a lot of things easier/smoother or more efficient, but there is a reason we don't do it (at least not yet), regardless of how noble the initial intent maybe.
2- And this is important, identity provider business is one of those things that have a real network effect, that means by definition and nature, in the IDP business there can not be dozen winners, it is a winner take all type of a game (or maybe a few - two, three) winners at most. NASCAR problem exists because no one wants to admit that it will not be one of the winners. But time will take care of this. For now support for xAuth seems to have become an admission of membership to "Second Tier IDP Club". after all if you think you are going to be one the winners, why would you want to remove your logo from the NASCAR race?
The essence of the solution is to create a centralized database (xauth.org) where users preferred IDPs are listed. For example if you use Google Friend Connect then xauth.org DB saves that preference for you. Now the publishers/RP that you visit, make a call to xauth.org (upon your visit) and learn that you prefer to "login" using GFC and only show that logo to you instead of a dozen logos from FB, Tweeter, Yahoo, AOL, Google, Microsoft, VeriSign and whoever else who jumps on federated ID band wagon.
My initial reaction (emphasis on initial) is "Are you serious?" and "Is it opt-in or opt-out" (apparently it is opt-out).
Two comments:
1- Of course collecting all people's information in one central database make a lot of things easier/smoother or more efficient, but there is a reason we don't do it (at least not yet), regardless of how noble the initial intent maybe.
2- And this is important, identity provider business is one of those things that have a real network effect, that means by definition and nature, in the IDP business there can not be dozen winners, it is a winner take all type of a game (or maybe a few - two, three) winners at most. NASCAR problem exists because no one wants to admit that it will not be one of the winners. But time will take care of this. For now support for xAuth seems to have become an admission of membership to "Second Tier IDP Club". after all if you think you are going to be one the winners, why would you want to remove your logo from the NASCAR race?
Monday, April 19, 2010
Identity Assertion Framework Talk @ Stanford Presentation
Here is the presentation for my talk today @ Stanford.
You can download the presentation for eBay's Identity Assertion Framework now. The talk is today (April 19, 2010), here is more information on time and place.
I have promised to write a bit more about IAF to a few people and I intend to keep my promise.
eBay Identity Assertion Framework (IAF)
View more presentations from farhangkassaei.
You can download the presentation for eBay's Identity Assertion Framework now. The talk is today (April 19, 2010), here is more information on time and place.
I have promised to write a bit more about IAF to a few people and I intend to keep my promise.
Wednesday, April 7, 2010
10 Decisions a Relying Party should make.
Open and federated identity schemes such as OpenID, InfoCard, FBConnect, GFC or sometimes even SAML getting a lot of attention these days, with OpenID capturing the biggest mind share.
A lot has been written (and standardized) about Open Identity protocols, transport binding and token format, (things that are primary concerns of IDPs - IDentity Providers). However I feel less attention has been paid to changes that Relying Parties (RPs) have to make to their systems (user experience and design, identity and account structure, session management etc.), after all there is a big difference between provisioning your own identity and performing your own primary authentication, v.s. relying on some one else to do it for you.
Here is a list of 10 things (you know it had to be 10 !) that you need to think about and decide if you are planning to be a Relying Party:
1. Decide which IDPs to accept: Not all IDP are created equal of course.
2. The design of the sign-in and registration page: in way that encourages the use of OpenID but not confuse users who do not use OpenID or do not know what it is.
3. Covering the "Information gap": How to capture information you need and is not provided by user's IDP during initial session, also determining whether you can call IDP (thru back channel) and ask for more (or updated) information about a user.
4. Privileges: Decide whether an OpenID user of your site has all the privileges of a local user or do they need to create a local account before they can perform certain activities.
5. Covering the "trust gap": Do you need IDP to provide some level of assurance (or verification) of the attributes it is providing you. For example if IDP provides user's home address, do you need this address to be verified?
6. Account Linking - decide whether you plan to become a true RP (i.e. no local account with local user name and password) or upon initial OpenID session, you plan to ask user to "register" with you site and create a local user name and password.
7. Session Management:Do you plan to sync you local session with IDP session length (or shorter or longer?) regardless will you "force re-authentication" for certain activities?
8. Profile Change Management: How do you plan to deal with users' who lose/forget their OpenID, is it important for you that a user
9. Account Cardinality: How many local account will you allow to be associated with one OpenID identifier, conversely, can an OpenID account be associated with multiple local accounts?
10. Logout: Whenan OpenID user logs out of your site, are you planning to report that to IDP for federated logout?
And if you are looking for controversy, consider the issue of "reporting adverse behavior" i.e. if a RP experienced an adverse behavior from a user with OpenID, should the RP report it to the IDP? If you consider IDPs equivalent to robots then, it seems like the Three laws of Robotics says no, but if you think of IDP more like credit bureaus (or evolving to become more like identity bureaus) then the ChexSystem indicates otherwise....
A lot has been written (and standardized) about Open Identity protocols, transport binding and token format, (things that are primary concerns of IDPs - IDentity Providers). However I feel less attention has been paid to changes that Relying Parties (RPs) have to make to their systems (user experience and design, identity and account structure, session management etc.), after all there is a big difference between provisioning your own identity and performing your own primary authentication, v.s. relying on some one else to do it for you.
Here is a list of 10 things (you know it had to be 10 !) that you need to think about and decide if you are planning to be a Relying Party:
1. Decide which IDPs to accept: Not all IDP are created equal of course.
2. The design of the sign-in and registration page: in way that encourages the use of OpenID but not confuse users who do not use OpenID or do not know what it is.
3. Covering the "Information gap": How to capture information you need and is not provided by user's IDP during initial session, also determining whether you can call IDP (thru back channel) and ask for more (or updated) information about a user.
4. Privileges: Decide whether an OpenID user of your site has all the privileges of a local user or do they need to create a local account before they can perform certain activities.
5. Covering the "trust gap": Do you need IDP to provide some level of assurance (or verification) of the attributes it is providing you. For example if IDP provides user's home address, do you need this address to be verified?
6. Account Linking - decide whether you plan to become a true RP (i.e. no local account with local user name and password) or upon initial OpenID session, you plan to ask user to "register" with you site and create a local user name and password.
7. Session Management:Do you plan to sync you local session with IDP session length (or shorter or longer?) regardless will you "force re-authentication" for certain activities?
8. Profile Change Management: How do you plan to deal with users' who lose/forget their OpenID, is it important for you that a user
9. Account Cardinality: How many local account will you allow to be associated with one OpenID identifier, conversely, can an OpenID account be associated with multiple local accounts?
10. Logout: Whenan OpenID user logs out of your site, are you planning to report that to IDP for federated logout?
And if you are looking for controversy, consider the issue of "reporting adverse behavior" i.e. if a RP experienced an adverse behavior from a user with OpenID, should the RP report it to the IDP? If you consider IDPs equivalent to robots then, it seems like the Three laws of Robotics says no, but if you think of IDP more like credit bureaus (or evolving to become more like identity bureaus) then the ChexSystem indicates otherwise....
Friday, April 2, 2010
Key to Scalability: Distributed System Development
Today I came across this nice presentation about Google internal architecture practices by Jeff Dean.plenty of valuable advice and common sense (the most uncommon of all senses). I just wanted to highlight one item that I feel is a bit under-appreciated - on page 20 when he talks about key attributes of distributed system, there is on bullet point that reads:
Development cycles largely decoupled
– lots of benefits: small teams can work independently
On one hand this is so obvious! After all they are "distributed" systems, how can they have coupled life cycle, on the other hand in so many people complain about lack of productivity and agility in large "distributed" systems. When you look closer, you find out that they have fairly decoupled system initally, more or less get the boundaries right, however they coupled the life cycles of all applications and services together !!
This means the whole organization releases with one giant push, the whole system all together. Everyone has to be on the same page, over time this unified "beat"brings down the boundaries and soon "the distributed" system becomes a monolith.
I will write a few more entries about the basic principles that enable true distributed (and autonomous) application development.
By the way, Here is eBay version of scalability advice (a bit dated but updating it is in my todo list) by Dan Pritchet.
Development cycles largely decoupled
– lots of benefits: small teams can work independently
On one hand this is so obvious! After all they are "distributed" systems, how can they have coupled life cycle, on the other hand in so many people complain about lack of productivity and agility in large "distributed" systems. When you look closer, you find out that they have fairly decoupled system initally, more or less get the boundaries right, however they coupled the life cycles of all applications and services together !!
This means the whole organization releases with one giant push, the whole system all together. Everyone has to be on the same page, over time this unified "beat"brings down the boundaries and soon "the distributed" system becomes a monolith.
I will write a few more entries about the basic principles that enable true distributed (and autonomous) application development.
By the way, Here is eBay version of scalability advice (a bit dated but updating it is in my todo list) by Dan Pritchet.
eBay Social Shopping w/ Google Friend Connect
Today, with Jay Patel's post on Google Social Web Blog, we released the alpha version of eBay Social Shopping gadget. It is a little cool Gadget that allows any sites (that is registered with Google Friend Connect), to surface eBay inventory and mix it with social functions such as recommendation to friend, rankings, sharing eBay activities (bid, buy, watch etc.) with friends etc.
You can read more about it by visiting ess.ebay.com and see our demos.
You can read more about it by visiting ess.ebay.com and see our demos.
Wednesday, March 31, 2010
Meetings kill Loose Coupling
There is a brilliant, yet underutilized, sociological observation called the Conway’s Law. It was stated by Mel Conway in his 1968 paper. It states that:
The key phrase is “communication structure”, that is roughly, but not always, equal to organization structure.
You may have not heard of or read his paper, but I am sure you have seen the effect of his observation:
If you have two teams called Application and Kernel, then chances are you end up with two deployment units called applications and kernel (jars or folders or zip files or any other form of bundling code), on the other hand if you engineering organization has two teams called Books and Games, then you end up with a book and a game application, if there is no other team/group, it is unlikely that you can see a kernel or core subsystem that encapsulate the common construct between the two.
Now, we all know about the principal of loose coupling, and how it enables flexibility, efficiency, increased productivity etc. One very effective way of creating loose coupling between two system (let’s call then consumer and producer) is to make sure that members of the producer team do not meet with members of consumer team! You may convey requirements to them, but forbid meetings. If there is not communication, it is hard to build hard coupling. It is a bit strange and counter-intuitive, but we have used this with success in building key infrastructure services.
I have found out that a good early predictor of the level of coupling (or quality of interfaces in general) of a system is the list of invitees to their early design meetings. Whenever one of few engineers from a future consumer is part of the meeting, there is a good indication that they systems will be somehow coupled (either thru the types or domain values of parameters passed or the way errors are handled, the marshalling of the result, or even the terminology used) – This of course is a generalization, the team somehow has to collect requirements, or share result s and get early feedback, this is all OK, but if your goal is to create “loosely coupled” system, you should make sure your communication structure, are loosely coupled as well.
Take a service that verifies a credit card number to ensure validity and that a provided name indeed matches credit card issuer record. This service may have a method/operation in its interface:
Result VerifyCreditCard(UserId id)
It assumes that somehow the service can obtain a credit card number from a supplied UserID. This is a very tightly coupled interface that shows the service provider has had too much knowledge about its consumer.
Here is a less tightly coupled (better) example:
Result VerifyCreditCard(CreditCard card, BuyerName buyerName)
This is not too bad, but the choice of “BuyerName” indicates that the provider has the knowledge that consumer (the one she probably met with) happens to deal with principals that are buyer.
Consider a loosely coupled version that one would probably write if there is no additional knowledge of potential consumers
Result VerifyCreditCard(CreditCard card, Name name)
Communication channels are very important interface design, this means people in each design meetings should be selected carefully, if system A should not be dependent on system B, the best way to ensure it, is to reduce communication between developers of system A and system B.
Any organization that designs a system will inevitably produce a design whose structure is a copy of the organization's communication structure.
The key phrase is “communication structure”, that is roughly, but not always, equal to organization structure.
You may have not heard of or read his paper, but I am sure you have seen the effect of his observation:
If you have two teams called Application and Kernel, then chances are you end up with two deployment units called applications and kernel (jars or folders or zip files or any other form of bundling code), on the other hand if you engineering organization has two teams called Books and Games, then you end up with a book and a game application, if there is no other team/group, it is unlikely that you can see a kernel or core subsystem that encapsulate the common construct between the two.
Now, we all know about the principal of loose coupling, and how it enables flexibility, efficiency, increased productivity etc. One very effective way of creating loose coupling between two system (let’s call then consumer and producer) is to make sure that members of the producer team do not meet with members of consumer team! You may convey requirements to them, but forbid meetings. If there is not communication, it is hard to build hard coupling. It is a bit strange and counter-intuitive, but we have used this with success in building key infrastructure services.
I have found out that a good early predictor of the level of coupling (or quality of interfaces in general) of a system is the list of invitees to their early design meetings. Whenever one of few engineers from a future consumer is part of the meeting, there is a good indication that they systems will be somehow coupled (either thru the types or domain values of parameters passed or the way errors are handled, the marshalling of the result, or even the terminology used) – This of course is a generalization, the team somehow has to collect requirements, or share result s and get early feedback, this is all OK, but if your goal is to create “loosely coupled” system, you should make sure your communication structure, are loosely coupled as well.
Take a service that verifies a credit card number to ensure validity and that a provided name indeed matches credit card issuer record. This service may have a method/operation in its interface:
Result VerifyCreditCard(UserId id)
It assumes that somehow the service can obtain a credit card number from a supplied UserID. This is a very tightly coupled interface that shows the service provider has had too much knowledge about its consumer.
Here is a less tightly coupled (better) example:
Result VerifyCreditCard(CreditCard card, BuyerName buyerName)
This is not too bad, but the choice of “BuyerName” indicates that the provider has the knowledge that consumer (the one she probably met with) happens to deal with principals that are buyer.
Consider a loosely coupled version that one would probably write if there is no additional knowledge of potential consumers
Result VerifyCreditCard(CreditCard card, Name name)
Communication channels are very important interface design, this means people in each design meetings should be selected carefully, if system A should not be dependent on system B, the best way to ensure it, is to reduce communication between developers of system A and system B.
Tuesday, March 30, 2010
Evolving Gracefully - Example I
In my posts, "What is Architecture", Part I and Part II, I argued that architecture is essentially what enables a system to evolve gracefully and traverse an optimal path in response to changes (requirements, assumptions, context, inputs etc.). In this post (and in a few more) I give examples of such changes and possible optimal/graceful (or non-optimal/disruptive) responses of a system.
Take "Accessibility Requirement" as an example. Few software systems are designed with the explicit goal of accessibility as one of the main architecture and design goals. However, some systems at some point must comply to certain accessibility standards and guidelines (it is good usability practices, the right thing to do, good business and the law) - see a very good introduction to accessibility from WebAIM.org here.
Now, if some one came one morning and asked you to make sure every image in every single HTML page of your site has an alt tag, what would be your response? Remember this maybe 1000s or image tag in 10s or 100s of applications produced by developers across three continents.
If your architecture (and the design and implementation of it) decoupled model construction from actual rendering, and a centralized rendering engine that takes a data structure (such as DOM) and uses a rendering strategy to produce XHTML, then your architecture (and you) has no problem responding to this new requirement easily. You'd simply make sure that when the render visit an![]() element, it finds an alt attribute. This is an optimal response to change. Although the system was not particullary designed with accessibility in mind, since it was built based on the right architecture, it can evolve to accommodate change.
element, it finds an alt attribute. This is an optimal response to change. Although the system was not particullary designed with accessibility in mind, since it was built based on the right architecture, it can evolve to accommodate change.
However, if the 1000s HTML pages on your site are produced by 100s of JSP scripts, a few PHP scripts, some XSL, a few instances of dynamically created![]() tags in JavsScript etc. You would have a nightmare on your hand. This is an example of architecture that can not evolve ...
tags in JavsScript etc. You would have a nightmare on your hand. This is an example of architecture that can not evolve ...
Take "Accessibility Requirement" as an example. Few software systems are designed with the explicit goal of accessibility as one of the main architecture and design goals. However, some systems at some point must comply to certain accessibility standards and guidelines (it is good usability practices, the right thing to do, good business and the law) - see a very good introduction to accessibility from WebAIM.org here.
Now, if some one came one morning and asked you to make sure every image in every single HTML page of your site has an alt tag, what would be your response? Remember this maybe 1000s or image tag in 10s or 100s of applications produced by developers across three continents.
If your architecture (and the design and implementation of it) decoupled model construction from actual rendering, and a centralized rendering engine that takes a data structure (such as DOM) and uses a rendering strategy to produce XHTML, then your architecture (and you) has no problem responding to this new requirement easily. You'd simply make sure that when the render visit an
However, if the 1000s HTML pages on your site are produced by 100s of JSP scripts, a few PHP scripts, some XSL, a few instances of dynamically created
Monday, March 29, 2010
Identity Assertion Framework (IAF) Talk at Stanford
I will give a talk about eBay's framework for handling federation, federated token services and distributed authentication - called IAF - at Stanford on Monday April 19th, 2010. Here is a brief description The talk is part of the Stanford Security Seminar.
This is an area that is poorly understood by software developer and architects that are new to security or authentication. I will write more about the topic of "authentication" and eBay's framework for handling it in more details. Look for under the label "Identity" and "Security".
This is an area that is poorly understood by software developer and architects that are new to security or authentication. I will write more about the topic of "authentication" and eBay's framework for handling it in more details. Look for under the label "Identity" and "Security".
Friday, March 26, 2010
What is Software Architecture - Part II
In part I, I offered my view of software architecture by illustrating what "architecture" does for you: Allows you to deal with change optimally. This is basically saying architecture is what allows a system to change with out changing fundamentally what it is (forgetting about Dialectics for a moment). In other words:
Architecture is what enables a system to evolve gracefully
You may ask, how else a system would change? How is this for an example? Don't let the glitz and glitter fool you. This is an example of architecture that fail to evolve according to the changes in its context and accumulation of demands for change finally resulted in its destruction. However, I doubt that you see an implosion of Taj Mahal - architect Ustad (Master) Ahmad Lahouri - any time soon.
Now you may say, well these are building, what do they have to do with software? I don't want to over play the building metaphor, but software systems acts similarly. How many times you have seen a multi million dollar investment in, say, customer support system or CRM system or messaging infrastructure or authorization system etc. only to scrap them two, or three years later by another multi million dollar system?
On the start up side, often the first and only concern is to make it work and to survive, but when time comes to scale, they often have to re-write from scratch, that is the software counterpart of a Vegas hotel implosion.
In my next post, I will give you a few software and system examples of graceful evolution courtesy of good architecture practice and "implosion" for lack thereof.
Thursday, March 25, 2010
What is Software Architecture - Part I
My job title carries the word “architect” - although my Mom never fails to point out that I am not a real architect like my brother is. This title among the software engineering community in general and in the Silicon Valley in particular almost always is received as an incomplete description of what a person does. People always expect an additional clarification; they give you an inquiring look “… so what is it exactly that you do?”
The title reminds me of “food supplement” industry, unlike drugs it is unregulated and anyone can claim anything from magical weight loss pill to cure for emphysema powder. In our industry too, anyone can claim the title and define it as he s/he sees fit. The title also conjures up images of a two-class software society: a lower class of software engineers who actually code and a ruling, elite class of architects that do not code or even read and understand code– and inevitably overtime lose touch with reality. Out of concern for the latter, some companies even eliminate the title altogether.
But what do exactly architects do?
I try to answer this question by answering the closely related question: What is Software Architecture?
Let me get to the bottom line first and explain later: I view architecture as a discipline that enables system to deal with change in optimally.
There are two key terms in this definition, change and “optimally”.
Let’s start with change.
Non-trivial software is a system, and like any other system is subject to change over time. The change happens in all aspects and along all dimensions: scale, cost, expectations, visibility, criticality, operating environment, competitive landscape, technology, economy, people, organization etc.
One prominent and widely known example of “change” is rapid growth in demand from a software system or what is commonly known as “scale”. Our general expectation of well architected system is to handle the scale gracefully and with no disruption. However some systems crash and need to be fully re-designed for the new level of demand (remember early days of Tweeter ?)
To be presicous, this type of scale is scalability to handle homoginous user i.e. all users of eBay were assumed to be individual buyers and sellers (no medium to large sellers), all facebook users were assumed to be college student or all users of an enterprise system could be assumed to be internal users.
Another example of change is scale of operation or non-homoginous user demand i.e. the system dose not necessary experience a change in volume of demand from one type of users, but has to handle demand from different types of users for example eBay wanting to deal with large merchants, or facebook wanting to open its platform to everyone (not just college students).
These were only two example of change in form of scale. What differentiate a well architected system from a “system that works” is how well systems respond to those changes.
The second key term in our definition was “optimally”. Optimally means the change can be absorbed and handled by the system with no (or minimum) disruption and in other words system is designed in a way that the scope of change is predetermined and extent of it is contained: no crisis, no building the system from scratch, no revolution! They system simply evolves along a smooth path. That is the essence of architecture (at least the software kind).
The pictures below depict the graceful and disruptive response to change:

This one, shows the same change scenario but one where change is handled gracefully, presumable with a well architected system.

In the next post, I will give a few examples to make this view of what architecture is clearer.
The title reminds me of “food supplement” industry, unlike drugs it is unregulated and anyone can claim anything from magical weight loss pill to cure for emphysema powder. In our industry too, anyone can claim the title and define it as he s/he sees fit. The title also conjures up images of a two-class software society: a lower class of software engineers who actually code and a ruling, elite class of architects that do not code or even read and understand code– and inevitably overtime lose touch with reality. Out of concern for the latter, some companies even eliminate the title altogether.
But what do exactly architects do?
I try to answer this question by answering the closely related question: What is Software Architecture?
Let me get to the bottom line first and explain later: I view architecture as a discipline that enables system to deal with change in optimally.
There are two key terms in this definition, change and “optimally”.
Let’s start with change.
Non-trivial software is a system, and like any other system is subject to change over time. The change happens in all aspects and along all dimensions: scale, cost, expectations, visibility, criticality, operating environment, competitive landscape, technology, economy, people, organization etc.
One prominent and widely known example of “change” is rapid growth in demand from a software system or what is commonly known as “scale”. Our general expectation of well architected system is to handle the scale gracefully and with no disruption. However some systems crash and need to be fully re-designed for the new level of demand (remember early days of Tweeter ?)
To be presicous, this type of scale is scalability to handle homoginous user i.e. all users of eBay were assumed to be individual buyers and sellers (no medium to large sellers), all facebook users were assumed to be college student or all users of an enterprise system could be assumed to be internal users.
Another example of change is scale of operation or non-homoginous user demand i.e. the system dose not necessary experience a change in volume of demand from one type of users, but has to handle demand from different types of users for example eBay wanting to deal with large merchants, or facebook wanting to open its platform to everyone (not just college students).
These were only two example of change in form of scale. What differentiate a well architected system from a “system that works” is how well systems respond to those changes.
The second key term in our definition was “optimally”. Optimally means the change can be absorbed and handled by the system with no (or minimum) disruption and in other words system is designed in a way that the scope of change is predetermined and extent of it is contained: no crisis, no building the system from scratch, no revolution! They system simply evolves along a smooth path. That is the essence of architecture (at least the software kind).
The pictures below depict the graceful and disruptive response to change:

This one, shows the same change scenario but one where change is handled gracefully, presumable with a well architected system.

In the next post, I will give a few examples to make this view of what architecture is clearer.

{kind=link}